背景
- AndroidアプリでKotlinを使用したので備忘録
- Kotlinの概念がかなりAdvancedなのでまとめる
NOTE:
基本
変数・定数
1
2
| var mutable = 20
val immutable = 10
|
constとvalの違い
constは主にコンパイル時に値が確定している定数を定義する場合に使用し、valは変更不可能な変数を定義する際に広く使用する。
| 特性 | const | val |
|---|
| 宣言のタイミング | コンパイル時に値が決定 | 実行時に値が決定 |
| 使用可能な場所 | トップレベルまたはobjectの中のみ | どこでも使用可能(クラス内、関数内、トップレベルなど) |
| 使用可能な型 | プリミティブ型とString型のみ | すべての型 |
| 初期化 | 宣言時に初期化必須 | 宣言後に初期化可能(ただし一度だけ) |
| パフォーマンス | コンパイル時決定のため若干向上 | 実行時に値が決定 |
| 参照の扱い | 値そのものがインライン展開 | 参照として扱われる |
1
2
3
4
5
| // const の例
const val MAX_COUNT = 100
object Constants {
const val API_KEY = "abcdef123456"
}
|
パターンマッチング
when式を使用して、関数型言語のパターンマッチングが可能。
1
2
3
4
5
| when (x) {
is Int -> println("It's an Int")
is String -> println("It's a String")
else -> println("Unknown type")
}
|
コレクション
1
2
| val list = listOf(1, 2, 3)
val map = mapOf("a" to 1, "b" to 2)
|
Range
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
| //1~10の範囲
for(i in 1..10){
print(i) //「12345678910」
}
//2~10の範囲で2刻み
for(i in 2..10 step 2){
print(i) //「246810」
}
//9~1の範囲(逆順)で2刻み
for(i in 9 downTo 1 step 2){
print(i) //「97531」
}
println()
//1~10の範囲。ただし終わりの値(10)は含まない
for(i in 1 until 10){
print(i) //「123456789」
}
println()
//a~zの範囲
for(i in 'a'..'z'){
print(i) // 「abcdefghijklmnopqrstuvwxyz」
}
//A~zの範囲で2刻み
for(i in 'A' until 'z' step 2){
print(i) // 「ACEGIKMOQSUWY[]_acegikmoqsuwy」
}
|
分解宣言と多重戻り値
1
2
3
4
5
6
7
8
9
10
11
12
13
| fun addAndMul(a: Int, b: Int): Pair<Int, Int>{
return Pair(a + b, a * b)
}
val (wa, seki) = addAndMul(2, 5)
println("和: $wa, 積: $seki") //「和: 7, 積: 10」
val result = addAndMul(2, 5)
//分解宣言は内部的にcomponentN関数を呼び出している
val wa2 = result.component1()
val seki2 = result.component2()
println("和: $wa2, 積: $seki2") //「和: 7, 積: 10」
|
data class
1
2
3
4
5
6
7
8
| //データクラスは自動でcomponentNというメソッドが定義されているので分解宣言がそのまま使える
data class Person(val firstName: String, val lastName: String, val age: Int)
……
//データクラスのインスタンスを作る
val tanaka = Person("一郎", "田中", 25)
//データクラスのオブジェクトを複数の変数に分解して代入する
val (mei, sei, age) = tanaka
println("姓: $sei, 名: $mei, 年齢: $age") //「姓: 田中, 名: 一郎, 年齢: 25」
|
型
代数的データ型
代数的データ型には主に2種類ある。
- 直積型(Product Types)
- 複数の値を同時に持つ型
- Kotlinでは、data classがこれに相当
- 直和型(Sum Types)
- 複数の型の中から1つを選択する型
- Kotlinでは、sealedクラスがこれに相当
直積型(Product Types)の例は次。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| class Person(
val name: String,
val age: Int,
val email: String
)
// 使用例
val john = Person("John Doe", 30, "john@example.com")
// デストラクチャリング
val (name, age, email) = john
println("Name: $name, Age: $age, Email: $email")
// コピーと修正
val olderJohn = john.copy(age = 31)
|
直和型の例
1
2
3
4
5
| sealed class ApiResult<out T> {
data class Success<out T>(val data: T) : ApiResult<T>()
data class Error(val message: String) : ApiResult<Nothing>()
object Loading : ApiResult<Nothing>()
}
|
- このApiResultは、「成功」「エラー」「読み込み中」という3つの異なる状態のいずれかを必ず取る
シンプルに直和型を表現したいときは、enumでもできる。
1
2
3
4
5
| enum class ApiResult {
SUCCESS,
ERROR,
LOADING
}
|
型エイリアス
typealiasを用いて型に別名をつけることができる。
1
2
| typealias Meter = Int
typealias Killometer = Int
|
型の確認(is)
is演算子で型チェックができる。
1
2
3
4
5
6
7
8
9
10
11
| println("ABC" is String) // true
println("ABC" !is String) // false
open class ClassA() {}
class ClassB(): ClassA() {}
var a = ClassA()
var b = ClassB()
println(a is ClassA) // true
println(a is ClassB) // false
println(b is ClassA) // true
println(b is ClassB) // true
|
型のキャスト(as, as?)
asを用いて、スーパークラスをサブクラスにキャストできる。
1
2
3
| open class Parent() {}
class Child(): Parent() {}
var c: Child = Parent() as Child
|
キャストできない場合は例外が発生するが、as?を用いるとキャストできない場合にnullを返す。
1
2
| var n1: Short? = 123
var n2: Int? = n1 as? Int?
|
関数
基本的な関数定義
1
2
3
4
| fun functionName(param1: Type1, param2: Type2): ReturnType {
// 関数の本体
return result
}
|
単一式関数
1
| fun double(x: Int): Int = x * 2
|
デフォルト引数
1
| fun greet(name: String = "Guest") = println("Hello, $name!")
|
名前付き引数
1
2
| fun createUser(name: String, age: Int) = User(name, age)
val user = createUser(age = 25, name = "John")
|
可変長引数(vararg)
1
| fun sum(vararg numbers: Int): Int = numbers.sum()
|
ローカル関数(関数内関数)
1
2
3
4
| fun outer() {
fun inner() = println("Inner function")
inner()
}
|
拡張関数
拡張関数は、既存のクラスに新しいメソッドを追加する機能。
1
| fun String.addExclamation() = this + "!"
|
インライン関数
- インライン関数はコンパイル時に関数呼び出しの箇所に関数の中身が直接挿入される
- パフォーマンス最適化が目的
1
| inline fun operation(a: Int, b: Int, op: (Int, Int) -> Int): Int = op(a, b)
|
高階関数
関数を引数や戻り値として扱う関数の事。
1
2
| fun operation(x: Int, y: Int, op: (Int, Int) -> Int): Int = op(x, y)
val result = operation(10, 20, { a, b -> a + b })
|
トレーリングラムダ(末尾ラムダ)
なお、高級関数の最後がラムダ式の場合は、そのラムダ式を括弧外に書ける。
1
2
| fun operation(x: Int, y: Int, op: (Int, Int) -> Int): Int = op(x, y)
val result = operation(10, 20) { a, b -> a + b }
|
下のように引数に入れるべきものを外に書けるメリットがある。
1
| list.filter { it > 0 }.map { it * 2 }
|
Jetpack ComposeのsetContentは次のように使うが、これも末尾ラムダの例。
1
2
3
4
5
6
7
8
9
10
11
12
| setContent {
AppTheme {
MainContent()
}
}
// 下と同じ
setContent({
EchoTimerTheme {
MainContent()
}
})
|
これは概ね次のように定義されている。
1
| fun setContent(content: @Composable () -> Unit)
|
ラムダ式
{x -> xxx}がそのまま関数になる。
1
| val sum = { x: Int, y: Int -> x + y }
|
関数型
型は(int) -> intのように定義する。
1
| val multiply: (Int, Int) -> Int = { x, y -> x * y }
|
演算子オーバーロード
1
| operator fun Point.plus(other: Point) = Point(x + other.x, y + other.y)
|
中置表記法
- DSLをKotlinで作れる機能
timesオペレーターが定義された
1
2
| infix fun Int.times(str: String) = str.repeat(this)
val result = 3 times "Hello "
|
テイルレック最適化
末尾再帰関数の定義も可能。
1
2
| tailrec fun factorial(n: Int, acc: Int = 1): Int =
if (n <= 1) acc else factorial(n - 1, n * acc)
|
ジェネリック関数
1
2
3
| fun <T> printArray(array: Array<T>) {
array.forEach { println(it) }
}
|
多重戻り値
- KotlinにはTuple型はないため、戻り値が2つ、3つ、4つ以上で型を使い分ける
- 受け取る際は分解宣言して受け取る
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| // 2つ
fun returnPair(): Pair<Int, String> {
return Pair(42, "Hello")
}
// 3つ
fun returnTriple(): Triple<Int, String, Boolean> {
return Triple(42, "Hello", true)
}
// 4つ以上で別々の型
data class Result(val value1: Int, val value2: String)
fun multipleValues(): Result {
return Result(42, "Hello")
}
// 4つ以上で同じ型
fun multipleValues2(): List<Int> {
return listOf(1, 2, 3, 4, 5)
}
|
UnitとNothing
値を返却しない関数は Unit関数として扱われる。
1
2
3
| fun printMessage(msg: String) {
println(msg)
}
|
常に例外を返却し、戻り値を戻すことのない関数は Nothing型関数として定義される。
1
2
3
| fun raiseError(msg: String): Nothing {
throw MyException(msg)
}
|
関数参照(::)
関数名の前に::をつけると、関数を参照するオブジェクトを得ることができる。
1
2
3
4
5
6
| fun add(x: Int, y: Int): Int = x + y
fun main() {
val method = ::add
println(method(3, 5))
}
|
移譲と遅延(by)
2つの委譲
2つの委譲とは
次の委譲で、クラスのアクセッサーやメソッドを委譲する事が可能。
- プロパティ委譲(Property Delegation)
- クラス委譲(Class Delegation)
プロパティ委譲
- 個々のプロパティの振る舞いを別のオブジェクト(デリゲート)に委譲する
byキーワードを使用して実装する- プロパティのgetter/setterの動作をカスタマイズするのに使用する
1
2
3
4
5
6
7
8
9
10
11
12
13
| class Example {
var name: String by Delegate()
}
class Delegate {
operator fun getValue(thisRef: Any?, property: KProperty<*>): String {
return "$thisRef, thank you for delegating '${property.name}' to me!"
}
operator fun setValue(thisRef: Any?, property: KProperty<*>, value: String) {
println("$value has been assigned to '${property.name}' in $thisRef.")
}
}
|
クラス委譲
- インターフェースの実装を別のオブジェクトに委譲する
- 継承の代替手段として使用される
- クラス宣言時に
byキーワードを使用して実装する
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| interface Printer {
fun print()
}
class PrinterImpl(val x: Int) : Printer {
override fun print() { print(x) }
}
class SomeObject(b: Printer) : Printer by b
fun main() {
val b = PrinterImpl(10)
SomeObject(b).print() // 10を出力
}
|
SomeObjectのインスタンスのPrinterインターフェイスのメソッドはPrinterImplに委譲されているという事。
遅延初期化
遅延初期化とは
遅延初期化とは、オブジェクトの生成やプロパティの初期化を、それが実際に必要になるまで遅らせる技術。
遅延初期化の主な利点:
- メモリ効率の向上
- 初期化コストの削減
- 循環依存の解決
- 相互に依存するオブジェクト間の初期化問題を解決できる
lateinit
クラスのプロパティは初期化が必要だが、lateinit を用いることで初期化を遅らせることができる。
lateinitには、次の制約がある。
- Int などのプリミティブ型には使用できない
- Null許容型には使用できない
- var 変数にしか使用できない
1
2
3
4
| class Foo {
lateinit var name: String // init()が呼ばれるまで初期化不要
fun init(name: String) { this.name = name }
}
|
by lazy(デリゲート)
lateinitと似たものに by lazyがある。
- 読み取り専用(val)プロパティに使用
- 最初にアクセスされたときに初期化され、その後は同じ値を返す
- スレッドセーフ
1
2
3
4
5
6
| class Example {
val lazyValue: String by lazy {
println("Computed!")
"Hello"
}
}
|
クラスのプロパティだけではなく、ローカル変数も遅延初期化ができる。
1
2
3
4
| val lazyValue: String by lazy {
println("computed!")
"Hello"
}
|
Observableの例。
1
2
3
| var name: String by Delegates.observable("initial value") {
prop, old, new -> println("$old -> $new")
}
|
Scoped Function
Scoped Functionとは
scoped functionは、オブジェクトのコンテキスト内で処理を行うための便利な関数群。
主に5つのスコープ関数がある。
- let
- run
- with
- apply
- also
5つの関数の違い
それぞれの違いをまとめると次になる。
| 関数名 | オブジェクトの参照方法 | 戻り値 | 主な使用目的 |
|---|
let | it | ラムダの結果 | null安全な呼び出し、ローカルスコープでの変数利用 |
run | this | ラムダの結果 | オブジェクトの初期化と結果の計算 |
with | this | ラムダの結果 | オブジェクトのプロパティやメソッドを繰り返し使用 |
apply | this | オブジェクト自体 | オブジェクトの設定、初期化 |
also | it | オブジェクト自体 | 追加の効果や検証、ロギング |
itとthisの違い
- it(暗黙の引数名)
- ラムダ式の引数として渡されるオブジェクトを指す
- オブジェクトを別の変数名で参照したい場合に便利
- this(レシーバ)
- ラムダ式のレシーバとして渡されるオブジェクトを指す
- オブジェクトのメンバーに直接アクセスできる
1
2
3
4
5
6
7
8
9
10
11
| // itの使用(let)
person.let {
println(it.name) // it.を使用
it.age = 30 // it.を使用
}
// thisの使用(apply)
person.apply {
println(name) // thisは省略可能
age = 30 // thisは省略可能
}
|
let関数
- オブジェクトをラムダ式の引数として提供
- 戻り値はラムダ式の結果
- 主にnull安全な呼び出しに使用
1
| val length = str?.let { it.length } ?: 0
|
run関数
- オブジェクトをレシーバ(
this)として提供 - 戻り値はラムダ式の結果
- オブジェクトの初期化と結果の計算を同時に行う場合に便利
1
2
3
4
| val result = person.run {
println(name)
age * 2
}
|
with関数
- オブジェクトをレシーバ(
this)として提供 - 戻り値はラムダ式の結果
- オブジェクトのプロパティやメソッドを繰り返し使用する場合に便利
1
2
3
4
| with(person) {
println(name)
println(age)
}
|
apply関数
- オブジェクトをレシーバ(
this)として提供 - オブジェクト自体を返す
- オブジェクトの設定に便利
1
2
3
4
| val person = Person().apply {
name = "John"
age = 30
}
|
also関数
- オブジェクトをラムダ式の引数として提供
- オブジェクト自体を返す
- 追加の効果や検証に使用
1
2
3
| val numbers = mutableListOf(1, 2, 3)
numbers.also { println("The list elements are: $it") }
.add(4)
|
Class
コンストラクタ(constructor)
2種類のコンストラクタ
Kotlin のクラスには2種類のコンストラクタがある。
- プライマリコンストラクタ(クラスに1つだけ)
- セカンダリコンストラクタ(0個以上持つことができる)
プライマリコンストラクタ
プライマリーコンストラクタの構文
- クラス名に直接指定する事で、プライマリーコンストラクタの引数を設定できる
- プライマリーコンストラクタは、以下のように記述する(constructorは省略するのが一般的)
1
| class クラス名 constructor(引数: データ型) {}
|
プライマリーコンストラクタのパラメーター
- プライマリーコンストラクタのパラメータで
valやvarを使用すると、自動的にクラスのプロパティとして定義される - また、プロパティにアクセス修飾子やデフォルト引数も付与できる
- プライマリーコンストラクタ or プライマリーコンストラクタのパラメータと呼ぶ
1
| class Person(private val name: String, public var age: Int = 10)
|
プライマリーコンストラクタの本体
- プライマリーコンストラクタの本体は
initで定義する - この
initでプライマリーコンストラクタのパラメータ処理をしていた場合は実質プライマリーコンストラクタの本体
1
2
3
4
5
6
7
| class Person(val name: String, var age: Int) {
init {
require(age >= 0) { "Age must be non-negative" }
name = "bob"
age = 10
}
}
|
セカンダリコンストラクタ
セカンダリコンストラクタの構文
- セカンダリーコンストラクタはクラス内に
constructorメソッドを使って定義するコンストラクタ - 一般的なコンストラクタとの違いは
this(引数)構文によって、直接or間接的にプライマリーコンストラクタを呼ばなければならない点 - セカンダリーコンストラクタの引数は、プライマリーコンストラクタの引数パラメータ(
this(引数1, 引数2))に渡される必要がある
1
| constructor(引数: データ型): this(引数)
|
1
2
3
4
| class Person(var name:String, var age: Int) {
// name=引数のname, age=10でプライマリーコンストラクタに渡される
constructor(name: String) : this(name, 10)
}
|
暗黙的なプライマリーコンストラクタ
一般的なクラス定義(this(引数))抜きをすると、暗黙的なプライマリーコンストラクタとみなされる。
1
2
3
4
5
6
7
8
9
| class Person {
var name: String
var age: Int
constructor(name: String, age: Int) {
this.name = name
this.age = age
}
}
|
直接呼び出し、関節呼び出し
Kotlinでは、セカンダリーコンストラクタは必ず直接的または間接的にプライマリーコンストラクタを this(引数)で呼び出す必要がある。
直接的な呼び出し
1
2
3
4
5
6
7
8
| class Person(val name: String) {
var age: Int = 0
// ここのthis(name)でプライマリーコンストラクタを呼び出している
constructor(name: String, age: Int) : this(name) {
this.age = age
}
}
|
間接的な呼び出し
1
2
3
4
5
6
7
8
9
10
11
12
13
| class Person(val name: String) {
var age: Int = 0
var email: String = ""
constructor(name: String, age: Int) : this(name) {
this.age = age
}
// ここが2つめのコンストラクタを使った間接的なプライマリーコンストラクタの呼び出し
constructor(name: String, age: Int, email: String) : this(name, age) {
this.email = email
}
}
|
初期化ブロック(init)
初期化ブロックとは
- 初期化ブロックは、プロパティの初期化を行うためのブロック
- クラスに
init { ... } で初期化ブロックを記述する - 初期化ブロックはコンストラクタが呼び出されるよりも前に呼び出される
1
2
3
4
5
| class Foo {
init {
println("Foo is created.")
}
}
|
なぜ初期化ブロック(init)が必要か
- それはプライマリーコンストラクタがあるから
- プライマリーコンストラクタは実質的にコンストラクタの引数部分のみを宣言する
- 故にプライマリーコンストラクタの関数の本体としてinitが必要という事
1
2
3
4
5
6
7
8
9
10
11
| class Person(val name: String, val age: Int = 0) { // ここがプライマリーコンストラクタの引数
// このinitがプライマリーコンストラクタの本体
init {
require(age >= 0) { "Age must be non-negative" }
}
}
// 使用例
val person1 = Person("Alice", 30)
val person2 = Person("Bob") // ageはデフォルト値の0が使用される
|
コンストラクタと初期化ブロックの違い
コンストラクタと初期化ブロックには以下のような違いがある。
承知しました。初期化ブロックとコンストラクターの主な違いを以下の表にまとめました。
| 特徴 | 初期化ブロック | コンストラクター |
|---|
| 定義方法 | init キーワードを使用 | クラス名の後(プライマリ)またはconstructorキーワード(セカンダリ) |
| 主な目的 | 共通の初期化ロジック | オブジェクト作成時の特定の初期化 |
| パラメータ | 直接受け取れない | 受け取ることができる |
| 実行タイミング | 記述(宣言)前のプロパティの初期化の後 | オブジェクト作成時 |
| 複数定義 | 可能(定義順に実行) | 可能(オーバーロード) |
| 再利用性 | すべてのコンストラクターで共通 | 特定の初期化シナリオに対応 |
| this キーワード | 使用可能 | 使用可能(他のコンストラクター呼び出しにも使用) |
| 戻り値 | なし | なし(暗黙的にオブジェクトインスタンスを返す) |
| アクセス修飾子 | 不要 | 必要に応じて使用可能 |
| プロパティ初期化との関係 | プロパティ初期化と交互に実行 | プロパティ初期化の後に実行 |
メンバの宣言順序と実行順序の注意
実行順番のルール
プロパティの初期化は次の3つの順番で行われる。
- プライマリーコンストラクタのパラメータの評価
- これはセカンダリーコンストラクタの
this()呼び出しによるモノも含む
- プロパティの初期化と初期化ブロック(
init)のコード宣言準の実行- これには、プライマリーコンストラクタで宣言されたプロパティも含む
- プロパティと初期化ブロックは宣言された順序で交互に実行される
- セカンダリーコンストラクタの本体の実行(もし呼び出されていれば)
実行順序の例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| class Example(val input: String) { // プライマリーコンストラクタの引数
// ファーストプロパティ
val first = println("First property")
// ファーストイニシャライザ
init {
println("First initializer block: $input")
}
// セカンダリープロパティ
val second = println("Second property")
// セカンダリーイニシャライザ
init {
println("Second initializer block")
}
// セカンダリーコンストラクタ
constructor(input: String, second: Int): this(input) {
println("Secondary constructor")
}
}
|
プライマリーコンストラクタの実行結果
- プライマリーコンストラクタが実行されるため、InputとしてHelloが入る
- その後に、プロパティとinitが宣言順に評価される
- セカンダリーコンストラクタはもちろん呼ばれない
1
2
3
4
5
6
7
8
| fun main() {
Example("Hello")
}
First property
First initializer block: Hello
Second property
Second initializer block
|
セカンダリーコンストラクタの実行結果
- プライマリーコンストラクタ(
this(引数))が最初に評価される - その後に、宣言順にプロパティとinitが実行される
- 最終的にセカンダリーコンストラクタが実行される
1
2
3
4
5
6
7
8
9
| fun main() {
Example("Hello", 5)
}
First property
First initializer block: Hello
Second property
Second initializer block
Secondary constructor
|
アクセッサー
メンバ変数に添えて、インデントがずれたような形でgetter/setterを定義できる。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| class Foo() {
var name: String = ""
set(value) {
println("__set__")
field = value
}
get() {
println("__get__")
return field
}
}
fun main() {
var a = Foo()
a.name = "Yamada" // __set__
println(a.name) // __get__
}
|
data class
1
| data class User(val name: String, val age: Int)
|
extends
- kotlinのクラスはデフォルトで継承不可能
- そのため、
openキーワードをつける
1
2
3
4
5
6
7
8
9
| open class Animal {
open fun makeSound() { println("Some sound") }
fun eat() { println("Eating") } // このメソッドはオーバーライド不可
}
class Dog : Animal() {
override fun makeSound() { println("Bark") } // OK
// override fun eat() { } // コンパイルエラー
}
|
ただし、抽象クラスはデフォルトでopen。
1
2
3
| abstract class Shape {
abstract fun draw() // 抽象メソッドは自動的にopen
}
|
:と親クラス名を指定して継承する。
1
2
| open class Animal(val name: String)
class Dog(name: String) : Animal(name)
|
なお、親クラスが引数なしのコンストラクタ(または引数がすべてデフォルト値を持つコンストラクタ)を持つ場合、括弧を省略できる。
1
2
| open class Animal
class Dog : Animal
|
明示的に呼び出したい場合は空の括弧を使用できる。
1
2
| open class Animal
class Dog : Animal()
|
implements
- interfaceはabstrct classと同様にopen
- kotlinのinterfaceは抽象プロパティも定義可能
1
2
3
4
5
6
7
8
| interface Speakable {
fun speak()
}
class Person : Speakable {
override fun speak() {
println("Hello!")
}
}
|
sealed class
- 制限された階層構造を定義するために使用される特別な種類のクラス
- sealedクラスのサブクラスは、同じファイル内か、ネストされたクラスとして定義する必要がある
- when式でsealedクラスを使用する場合、コンパイラは全てのサブクラスが処理されているかチェックする
例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| sealed class ApiResult<out T> {
data class Success<out T>(val data: T) : ApiResult<T>()
data class Error(val message: String) : ApiResult<Nothing>()
object Loading : ApiResult<Nothing>()
}
fun handleApiResult(result: ApiResult<String>) {
when (result) {
is ApiResult.Success -> println("成功: ${result.data}")
is ApiResult.Error -> println("エラー: ${result.message}")
is ApiResult.Loading -> println("読み込み中...")
}
}
// 使用例
val successResult = ApiResult.Success("データ取得成功")
val errorResult = ApiResult.Error("ネットワークエラー")
val loadingResult = ApiResult.Loading
handleApiResult(successResult)
handleApiResult(errorResult)
handleApiResult(loadingResult)
|
innnerクラス
innerはネストされたクラスが内部クラスであることを示す。
1
2
3
4
5
| class A {
inner class B { ... }
}
var obj = A().B()
|
Generics
型制約
- Genericsでも型に制約をかけることができる
- 下記では、IntやDoubleなど、Numbe のサブクラスに制約している
1
2
3
4
5
6
| class Foo<T: Number>(val value: T)
fun main() {
val a1 = Foo(123)
println(a1.value + 1) // 124
}
|
out
out キーワードはサブクラスをスーパークラスに入れられる。
Javaでは以下のGenericsのUp Castは許されていない。
1
2
3
4
5
6
7
8
9
| // Java
interface Nextable<T> {
T nextT();
}
void demo(Nextable<String> strs) {
Nextable<Object> objects = strs; // !!! Not allowed in Java
// ...
}
|
Kotlinはそれができる。
1
2
3
4
5
6
7
8
| interface Nextable<out T> {
fun nextT(): T
}
fun demo(strs: Nextable<String>) {
val objects: Nextable<Any> = strs // This is OK
// ...
}
|
in
in キーワードはスーパークラスをサブクラスに入れられる。
1
2
3
4
5
6
7
8
9
| interface Comparable<in T> {
operator fun compareTo(other: T): Int
}
// NOTE: Numberのsubtypeはdouble
fun demo(x: Comparable<Number>) {
x.compareTo(1.0)
val y: Comparable<Double> = x // ok
}
|
inとoutの違い
inとoutの違いは次になる。
| 特徴 | in(反変性) | out(共変性) |
|---|
| キーワード | in | out |
| 変性 | 反変性(Contravariance) | 共変性(Covariance) |
| 主な用途 | コンシューマー(消費者) | プロデューサー(生産者) |
| 許可される操作 | 引数として受け取る(入力) | 戻り値として返す(出力) |
| 禁止される操作 | 戻り値として返す(出力) | 引数として受け取る(入力) |
| 型の関係 | スーパータイプを受け入れる | サブタイプを返すことができる |
| 代入の方向 | スーパータイプからサブタイプへ | サブタイプからスーパータイプへ |
| 安全性の保証 | 入力の型安全性 | 出力の型安全性 |
| コード例 | interface Comparable<in T> | interface List<out T> |
Object
Object式(匿名クラス)
- Object式は、Kotlinで匿名クラスを作成するための機能
- Java の匿名内部クラスに相当する
1
2
3
4
| val myObject = object {
val property = "Hello"
fun method() = "World"
}
|
インターフェイスの実装
1
2
3
4
5
6
7
8
9
10
| interface Greeter {
fun greet()
}
val englishGreeter = object : Greeter {
override fun greet() {
println("Hello!")
}
}
|
Object宣言(シングルトン)
Kotlinのobject宣言を使用すると、シングルトンオブジェクトを簡単に作成できる。
1
2
3
4
5
6
7
8
9
10
11
| object MySingleton {
val CONSTANT_VALUE = 42
fun printHello() {
println("Hello from Singleton")
}
}
fun main() {
println(MySingleton.CONSTANT_VALUE)
MySingleton.printHello()
}
|
Companion Object(Static Member)
- companion objectは、Kotlinの特有の機能で、Javaのstaticメンバーに似た機能を提供する
- Kotlinでは静的メンバーという概念が直接存在しないため、companion objectを使ってこれを実現する
コンパニオンオブジェクトの例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| class MyClass {
companion object {
const val CONSTANT_VALUE = 42
fun printHello() {
println("Hello from Companion Object")
}
}
}
fun main() {
println(MyClass.CONSTANT_VALUE) // 42
MyClass.printHello() // Hello from Companion Object
}
|
名前付きコンパニオンオブジェクトの例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| class MyClass {
companion object NamedCompanion {
const val CONSTANT_VALUE = 42
fun printHello() {
println("Hello from Named Companion Object")
}
}
}
fun main() {
println(MyClass.NamedCompanion.CONSTANT_VALUE) // 42
MyClass.NamedCompanion.printHello() // Hello from Named Companion Object
}
|
Null対応
Any
- Kotlinのクラスは全て「Any」というクラスを継承している
- Anyクラスは非Null型として定義された全てのクラスのスーパークラス
- つまり、Kotlinのクラスは全て非Null型になる
- 故に、KotlinではNull許容型であるJavaのObjectのサブクラスとなることはできない
?付きタイプ
?を型につけて宣言する事でnullable、オプショナル、null Unionな型にできる。
1
2
| var a: String? = "はろー" //String型の変数
a = null // ok
|
.?演算子
セーフコールでアクセスするための演算子。
1
2
3
4
5
| var d: String? = null
println(d?.length) //エラーは起きない。「null」が表示される
var e: String? = "はろはろ"
println(e?.length) //「4」が表示される
|
:?演算子
:?演算子(エルビス演算子)は参考演算子を短くしたようなデフォルト付きの演算子。
1
2
3
| //?:演算子でgetName関数の結果がnullだった場合の値を設定
val name2 :String = getName() ?: "名なしの権兵衛"
println(name2)
|
!!演算子
NullPointerExceptionを発生する形でアクセスするための演算子。
1
2
3
4
| //!!演算子を使ってnullの入ったNull許容型を無理やり非Null型に変換して参照
var f: String? = null
//コンパイルはできるが、実行時にめでたくNullPointerException発生
println(f!!.length)
|
Coroutineのアーキ
Structured Concurrency
Structured Concurrencyとは
- Structured Concurrency(構造化並行処理)はプログラミング言語における並行処理、非同期処理のAPIのパラダイムの一つ
- 並行処理をより安全で予測可能にし、エラー処理や資源管理を改善することを目的としている
- KotlinはStructured Concurrencyを採用している
以下が特徴となる。
- 階層構造:
- コルーチンは親子関係を持つ階層構造で組織される
- 子コルーチンは親コルーチンのコンテキスト内で実行される
- ライフサイクル管理:
- 親コルーチンは、全ての子コルーチンが完了するまで終了しない
- これにより、処理の完了を確実に把握できる
- エラー伝播:
- 子コルーチンで発生した未処理の例外は、親コルーチンに自動的に伝播する
- これにより、エラー処理が簡素化される
- キャンセル伝播:
- 親コルーチンがキャンセルされると、そのすべての子コルーチンも自動的にキャンセルされる
- スコープ:
- coroutineScope や supervisorScope などの関数を使用して、明示的にスコープを定義できる
Structured Concurrencyの例
- coroutineScope 内で2つの非同期処理(async)を開始している
- coroutineScope は、すべての子コルーチンが完了するまで終了しない
- いずれかの子コルーチンで例外が発生した場合、他の子コルーチンはキャンセルされ、例外が親に伝播する
1
2
3
4
5
6
7
8
9
10
11
12
| suspend fun fetchUserData() = coroutineScope {
val userDeferred = async { fetchUser() }
val friendsDeferred = async { fetchFriends() }
try {
val user = userDeferred.await()
val friends = friendsDeferred.await()
// 両方のデータの処理
} catch (e: Exception) {
// エラー処理
}
}
|
平行制御
4つの平行制御とは
Kotlinのコルーチンの平行制御には次の4つのタイプがある。
- Channel
- 複数のコルーチン間でデータや信号を交換するためのパイプラインとして機能する
- 生産者-消費者パターンに適している
- Flow
- 非同期に計算される値のシーケンスを表現する
- データ変換、フィルタリング、結合などの操作が容易
- Mutex
- 一度に1つのコルーチンのみがクリティカルセクションにアクセスできるようにする
- 共有リソースへの同時アクセスを防ぐ
- Semaphore
- 指定された数のコルーチンが同時にリソースにアクセスできるようにする
- リソースプールの管理に適している
4つの平行制御の比較
4つの平行制御があり、それぞれの違いは以下。
| 特性 | Channel | Flow | Mutex | Semaphore |
|---|
| 主な用途 | コルーチン間の通信 | 非同期データストリーム処理 | 相互排他制御 | リソースへのアクセス制限 |
| データの流れ | 生産者から消費者へ | 上流から下流へ | N/A | N/A |
| ホット/コールド | ホット | コールド(デフォルト) | N/A | N/A |
| バックプレッシャー | 自然にサポート | 明示的に実装可能 | N/A | N/A |
| 複数の受信者 | 通常1つ(ファンアウトも可能) | 複数可能 | N/A | N/A |
| 並行アクセス | 安全 | 安全 | 1つのコルーチンのみ | 指定数のコルーチン |
| キャンセル伝播 | サポート | サポート | N/A | N/A |
| バッファリング | 可能 | 可能 | N/A | N/A |
| 主な操作 | send/receive | emit/collect | lock/unlock | acquire/release |
| 用途例 | タスクキュー、イベント配信 | UI更新、データ変換 | 共有リソースの保護 | 接続プールの制御 |
Coroutineの種類
Coroutineの種類
KotlinのCoroutinesは次を提供する。
| 名前 | 関数 | 返す型 |
|---|
| ワンショット(戻り値なし) | launch{} | Job |
| ワンショット(戻り値あり) | async{} | Deferred<T> |
| ホットストリーム(複数の値) | Channel | Channel<T> |
| コールドストリーム(複数の値) | Flow | Flow<T> |
ワンショット
ワンショットとは一度だけ実行される関数の事。
ホットストリームとコールドストリームの違い
- ホットストリーム
- コレクターの有無に関わらず、データを生成し続ける
- 常にアクティブで、リソースを継続的に消費する
- コールドストリーム
- コレクターが要求したときのみデータを生成する
- 必要なときのみリソースを使用し、それ以外はアイドル状態となる
FlowとChannel
FlowとChannelの違い
FlwoとChannelをよく使うが次の点が大きく違う。
- Channel
- アクター
- 送信者(sender)と受信者(receiver)の関係
- 関係
- 消費モデル
- 競合的な消費モデル
- 送信された値は、1つの受信者によってのみ消費される
- つまり、複数のreceiverがいたら早い者勝ちになる
- Flow
- アクター
- 生産者(emitter)と収集者(collector)の関係
- 関係
- 消費モデル
- 非競合的な消費モデル
- 送信された値は、全ての受信者に届く
- つまり、複数のreceiverがいても確実に届く
FlowとChannneの図
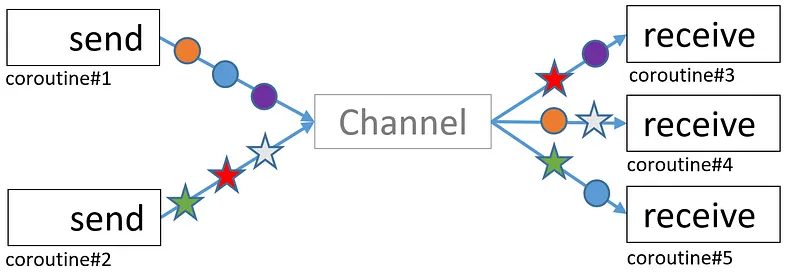
- Channelは値は早いもの勝ちになる
- channelのキューの値を取得する
- 複数の受信者がある場合、各値は1つの受信者にのみ届く
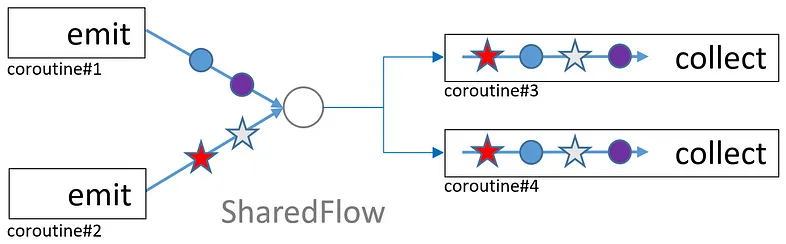
- Flowの値は全てのCollectorに届く
- 各Collectorは独立してFlowの全シーケンスを受け取る
- 複数のCollectorが同じFlowをcollectできるが、それぞれ独立した実行となる

- SharedFlowは、分かりやすく言うと、Channelの非競合的な消費モデル版
- 実際的にはboradcast channelのように機能する
- collect/collectorではなく、subscribe/subscriberと呼ばれる
Flow
Flwoのアクター
- コレクター(Collector)
- ストリームのコレクター(Collector)は、ストリーム処理の終端操作の一つ
- ストリームの要素を集約して最終的な結果を生成するための機能
collect()メソッドを使用する
- エミッター(Emitter):
- データを生成し、ストリームに送り出す役割を果たす
- 例:
emit() 関数を使用してデータを送信する
Flowとは
- Flowとは非同期に計算される値のシーケンスを表現するインターフェース
- 収集者が要求したときのみデータを生成する(コールドストリーム)
1
2
3
4
5
6
| flow {
for (i in 1..3) {
delay(100)
emit(i)
}
}.collect { value -> println(value) }
|
StateFlowとMutableStateFlowとは
StateFlowの主な特徴
- 常に値を保持
- ホットストリーム
- 値の重複排除
- 同じ値が連続して設定されても、収集者には通知されない
- 最新値の即時提供
- 新しい収集者は即座に最新の値を受け取る
- stateFlowはcollectしたら必ずそのcollectした瞬間に一回データが流れてくる
MutableStateFlowの特徴
- 値の変更が可能
- その他の特徴はStateFlowと同じ(常に値を保持、ホットストリーム、値の重複排除など)
StateFlowの例
以下はAndroidでViewModelとStateFlowを使ったFlowの例。
1
2
3
4
5
6
7
8
9
10
11
12
13
| // privateで変えられる、setter用
private val _keepScreenOn = MutableStateFlow(settingsPreferences.getBoolean("keepScreenOn", false))
// publicで変えられない、getter用
val keepScreenOn: StateFlow<Boolean> = _keepScreenOn
// 利用
lifecycleScope.launch { // AndroidのLifecycleのScope
viewModel.keepScreenOn.collect { keepOn -> // collectorの処理となる
if (keepOn) {
xxx
}
}
}
|
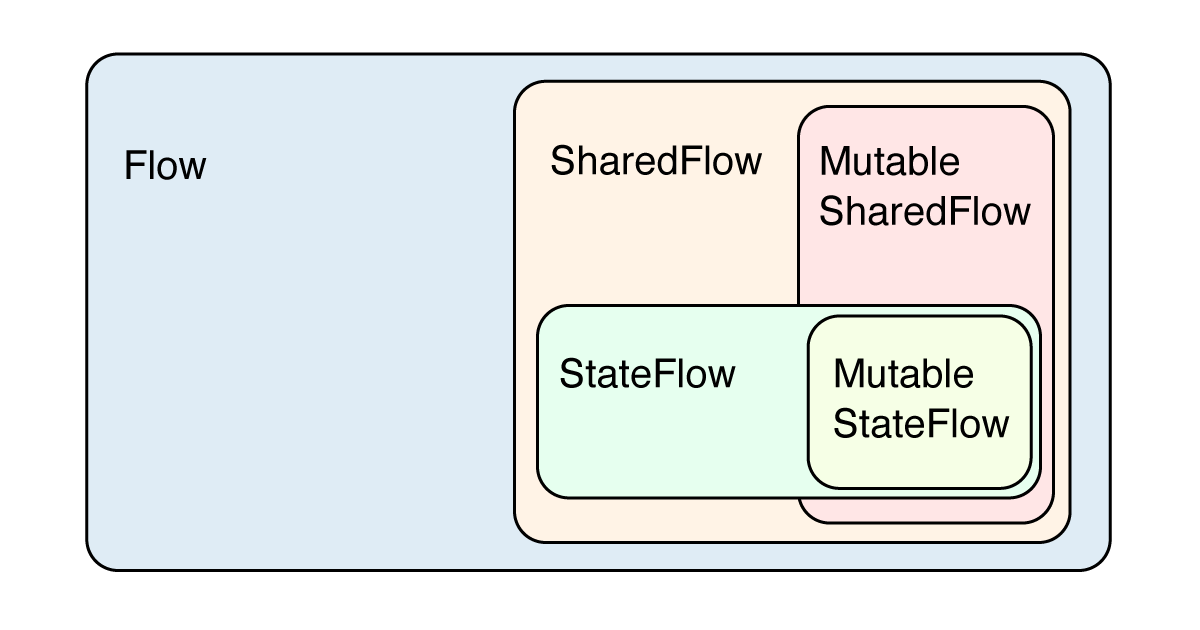
Flowの種類
Flow, SharedFlow, StateFlowなどの違いは以下。
複数のcollectの注意点
1つのコルーチンビルダーで複数のflowをcollectすると、2個目以降はcollectされないので注意。
1つのcollectの例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
| import kotlinx.coroutines.*
import kotlinx.coroutines.flow.*
fun main() = runBlocking {
val scope = CoroutineScope(Dispatchers.Default)
val myStateFlow = MutableStateFlow(0)
scope.launch {
myStateFlow.collect { value ->
println("Collected value: $value")
}
}
delay(200)
// 出力: Collected value: 0 (即座に現在の値が発行される)
myStateFlow.value = 1
delay(200)
// 出力: Collected value: 1
myStateFlow.value = 1
delay(200)
// 重複値なので発行されない
myStateFlow.value = 2
delay(200)
// 出力: Collected value: 2
}
|
その結果
1
2
3
| Collected value: 0
Collected value: 1
Collected value: 2
|
2つのcollectの例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
|
import kotlinx.coroutines.*
import kotlinx.coroutines.flow.*
fun main() = runBlocking {
val scope = CoroutineScope(Dispatchers.Default)
val myStateFlow = MutableStateFlow(0)
val myStateFlow2 = MutableStateFlow(0)
scope.launch {
myStateFlow.collect { value ->
println("Collected myStateFlow: $value")
}
myStateFlow2.collect { value ->
println("Collected myStateFlow2: $value")
}
}
delay(200)
// 出力: Collected myStateFlow: 0 (即座に現在の値が発行される)
myStateFlow.value = 1
delay(200)
// 出力: Collected myStateFlow: 1
myStateFlow.value = 1
delay(200)
// 重複値なので発行されない
myStateFlow.value = 2
delay(200)
// 出力: Collected myStateFlow: 2
myStateFlow2.value = 1
delay(200)
delay(2000)
}
|
その結果(myStateFlow2の現在の値とcollectが発生していない)
1
2
3
| Collected myStateFlow: 0
Collected myStateFlow: 1
Collected myStateFlow: 2
|
myStateFlow2が動かない理由は、最初のcollectが完了(この場合は永続的な監視を終了)するまで、次のcollectは開始されないから。
Channel
Channelのアクター
- プロデューサー(Producer):
- 特にChannelにおいて、データを生成する側を指す
send() メソッドを使用してデータを送信する
- コンシューマー(Consumer):
- データを受け取って処理する側を指す
- Collectorと同義で使われることもある
Channnelとは
- Channelは、Kotlinのコルーチンライブラリで提供される、非同期通信のためのプリミティブ
- 主に複数のコルーチン間でデータを安全に受け渡すために使用される
- Flowはコールドストリームだったが、Channelはホットストリーム
主な特徴:
- ホットストリーム
- スレッドセーフ
- バッファリング
- バックプレッシャー(back pressure)
Channelの種類
Channelにはいくつかの種類がある。
- Rendezvous (容量0)
- Buffered
- Unlimited
- Conflated
チャンネルの例
チャネル(Channel)とは、コルーチン間の通信に使用する。
1
2
3
4
5
6
7
8
9
10
11
12
| val channel = Channel<Int>()
launch {
for (i in 1..5) {
channel.send(i)
}
channel.close()
}
for (value in channel) {
println(value)
}
|
suspend
suspendとは
suspendキーワードはcoroutineの中核のキーワード。
- 形式:suspendは関数修飾子
suspend func getXXX(): String {}みたいに使用する
- 目的:非同期関数を定義する
- JSやPythonでいうasyncキーワードと同じ
特徴:
- 関数自体を中断可能(
suspendable)にする - 他のsuspend関数やCoroutineBuilder内でのみ呼び出せる
- 結果を直接返す(非同期的に)
suspend関数
- suspend関数は、Kotlinのコルーチンシステムの中核をなす重要な概念
- suspend関数はsuspendキーワードを使って定義される関数で、実行を一時停止し、後で再開することができる
- JSでいう、
async関数のようなもの
1
2
3
4
5
6
| suspend fun fetchUserData(): UserData {
// 非同期処理
val userId = fetchUserId() // サスペンドポイント1
delay(100) // サスペンドポイント2
return fetchUserDetails(userId) // サスペンドポイント3
}
|
launchやasyncとsuspendの違い
asyncとlaunchは関数で、suspendは関数修飾子。
| 特性 | async/launch | suspend |
|---|
| 使用方法 | 直接呼び出して新しいコルーチンを開始する | 関数を定義する際に使用し、その関数を中断可能にする |
| コンテキスト | CoroutineScope内でのみ使用可能 | 定義時に使用し、他のsuspend関数やコルーチン内から呼び出される |
| 目的 | 新しいコルーチンを作成し、並行処理を開始する | 既存の関数を非同期的に実行可能にする |
suspendとdelay()、await()
- suspend修飾子を使用すると、
delay()やawait()などの中断可能な関数を使用できるようになる - これらの関数は「サスペンドポイント」として機能し、コルーチンの実行を一時的に中断し、後で再開することができるようになる
サスペンドポイント
- 通常、他のサスペンド関数を呼び出す箇所がサスペンドポイントとなる
- 例えば、
delay()、await()、 他のカスタムサスペンド関数の呼び出しなど
違い
delay()- 指定した時間だけコルーチンの実行を中断する
- スレッドをブロックせずに待機できる
await()Deferred<T>の結果を待つために使用する- 結果が利用可能になるまでコルーチンを中断する
suspend関数の例
以下がdelayとawaitを使った例。
1
2
3
4
5
6
7
8
9
10
| suspend fun fetchUserData(): UserData {
delay(1000) // ネットワーク遅延をシミュレート
return UserData("John", 30)
}
suspend fun processUser() {
val deferred = async { fetchUserData() }
val userData = deferred.await() // 結果が得られるまで中断
println("User: ${userData.name}")
}
|
Coroutineの使い方
3つのSteps
3つのCoroutineのSteps
大まかに言うと次の3つの流れでコルーチンを使う。
- ディスパッチャーの決定(どのスレッドを使うか)
- スコープの決定(どのライフサイクルを使うか)
- ビルダーの決定(どんなコルーチン処理をするか)
3つのStepsの例
次のViewModelの例はフローに従っている。
- ディスパッチャー:Dispatchers.IO(ネットワーク呼び出し)とDispatchers.Main(UI更新)を使用
- スコープ:viewModelScope(ViewModelのライフサイクルに紐づく)
- ビルダー:launch(結果を直接返さない処理)
1
2
3
4
5
6
7
8
9
10
| class MyViewModel : ViewModel() {
fun loadData() {
viewModelScope.launch(Dispatchers.IO) {
val result = performNetworkCall()
withContext(Dispatchers.Main) {
updateUI(result)
}
}
}
}
|
CoroutineDspatcher
CoroutineDspatcherとは
- CoroutineDspatcherは、コルーチンがどのスレッドまたはスレッドプールで実行されるかを決定するコンポーネント
- 扱うタスクの性質に応じてディスパッチャーを選択する必要がある
CoroutineDspatcherの種類
- Dispatchers.Default
- CPU集約型のタスクに適している
- バックグラウンドスレッドプールを使用する
- 複数のスレッドで並行実行される可能性が高い
- Dispatchers.Main
- UI操作に適している(Android、JavaFXなど)
- メインスレッド(UIスレッド)上で実行される
- 同時に1つのタスクのみが実行される
- Dispatchers.IO
CoroutineDspatcherの例
次のように使用する。
1
2
3
4
5
6
7
8
9
10
11
12
| launch(Dispatchers.IO) {
// I/O操作を行うコード
}
withContext(Dispatchers.Default) {
// CPU集約型の処理
}
val deferredCPU = async(Dispatchers.Default) {
// CPU集約型の処理
}
val resultCPU = deferredCPU.await()
|
CoroutineScope
CoroutineScopeとは
- CoroutineScopeは、コルーチンの実行範囲を定義し、その生存期間を管理するためのコンテキスト
- キャンセル処理やポーズなどのコンテキストを決めるスコープ
- Pythonで言うところのリソースの自動開放をする
withキーワードに近い
1
2
3
4
| with open('file.txt', 'r') as file:
content = file.read()
print(content)
# このブロックを抜けると自動でclose
|
CoroutineScopeの種類
- GlobalScope
- CoroutineScope
- lifecycleScope
- Android の LifecycleOwner に紐づいたスコープ
- viewModelScope
CoroutineScopeが必要な理由
CoroutineScopeは非同期処理の管理、制御、およびリソースの効率的な利用を可能にする為に必要。
- 構造化並行性
- コルーチンの階層構造を管理し、親子関係を確立する
- 親スコープがキャンセルされると、子コルーチンも自動的にキャンセルされる
- ライフサイクル管理
- コルーチンの開始と終了を制御する
- アプリケーションの特定のライフサイクル(例:Androidのアクティビティ)に合わせてコルーチンを管理できる
- リソース管理
- コルーチンが使用するリソースを適切に解放する
- メモリリークを防ぐために重要
CoroutineScopeの使用例
Dispatchers.DefaultはCPU 集約型タスクのために最適化されたスレッドプールを使用するディスパッチャー- つまり、Dispatcherを指定する事でコルーチンのスレッドを決定する
1
2
3
4
5
6
7
8
9
10
11
| val scope = CoroutineScope(Dispatchers.Default)
scope.launch {
// この中で複数のコルーチンを起動できる
val result1 = async { fetchData1() }
val result2 = async { fetchData2() }
println("Results: ${result1.await()}, ${result2.await()}")
}
// スコープのキャンセル(必要に応じて)
scope.cancel()
|
- launchもasyncもCoroutineBuilder関数
- 一つの親コルーチン(launch)の中に、2つの子コルーチン(async)が存在する形になる
CoroutineBuilder
CoroutineBuilderとは
- CoroutineBuilderは、Kotlinのコルーチンを作成し、開始するための関数
- これらは新しいコルーチンを構築し、その実行を制御する
-
launch, asyncなどがある
CoroutineBuilderの使い方
launch
- 結果を返さない新しいコルーチンを開始する
- Job オブジェクトを返す(キャンセルなどの制御に使用)
fire and forget(実行しっぱなし)タイプの非同期タスクに適している
1
2
3
| val job = launch {
// コルーチンの処理
}
|
async
- 結果を返すコルーチンを開始する。
Deferred<T> でT型の戻り値のオブジェクトを返すawait() メソッドで結果を取得できる
1
2
3
4
| val deferred = async {
return 42
}
val result = deferred.await() // 42
|
runBlocking
- 現在のスレッドをブロックし、その中でコルーチンを実行する
- 主にテストや main 関数でコルーチンを実行する際に使用
1
2
3
4
| runBlocking {
delay(1000L)
println("After delay")
}
|
coroutineScope
- 新しいCoroutineScopeを作成し、すべての子コルーチンが完了するまで待機する
- サスペンド関数内で使用され、親コルーチンのコンテキストを継承する
1
2
3
4
| suspend fun doSomething() = coroutineScope {
launch { task1() }
launch { task2() }
}
|
supervisorScope
- coroutineScope と似ているが、子コルーチンの例外が他の子や親に伝播しない
- エラー耐性のある操作に適している
1
2
3
4
| supervisorScope {
launch { riskyTask1() }
launch { riskyTask2() }
}
|
withContext
- 指定されたコンテキストで、コルーチンのブロックを実行する
- 主にディスパッチャーを切り替えるのに使用
1
2
3
| withContext(Dispatchers.IO) {
// I/O操作
}
|
CoroutineBuilderの使い分け
いくつかCoroutineBuilderがあるが、次のように使い分ける。
| ビルダー | 主な用途 | 戻り値 | 特徴 | 典型的な使用場面 |
|---|
| launch | 結果を返さない非同期タスク | Job | 「発射して忘れる」タイプの処理 | バックグラウンド処理、ログ記録、イベント送信 |
| async | 結果を返す非同期タスク | Deferred | 並列処理、結果の取得が必要な場合 | 複数のAPIリクエスト、並列計算 |
| runBlocking | メイン関数やテストでのコルーチン実行 | T (ブロック内の最後の式の結果) | 現在のスレッドをブロック | テスト、スクリプトのメイン関数 |
| coroutineScope | 複数の非同期操作のグループ化 | T (ブロック内の最後の式の結果) | すべての子が完了するまで待機 | 関連する複数の非同期タスクの実行 |
| supervisorScope | エラー耐性のある操作 | T (ブロック内の最後の式の結果) | 子の失敗が他に影響しない | 独立した複数のタスク実行、エラー分離が必要な場合 |
| withContext | 特定のコンテキストでの実行 | T (ブロック内の最後の式の結果) | コンテキスト(主にディスパッチャー)の切り替え | I/O操作、計算集約型タスク、UI更新 |
その他
アクターモデル
- アクターモデルの基本概念
- アクターは独立した計算単位で、自身の状態を持ち、メッセージを受け取って処理する
- アクター同士は直接通信せず、メッセージパッシングを通じて相互作用する
- 各アクターは独自のメールボックス(メッセージキュー)を持つ
kotlinでのアクターモデルの例。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
| import kotlinx.coroutines.*
import kotlinx.coroutines.channels.*
sealed class CounterMsg
object IncCounter : CounterMsg()
class GetCounter(val response: CompletableDeferred<Int>) : CounterMsg()
fun CoroutineScope.counterActor() = actor<CounterMsg> {
var counter = 0 // アクターの状態
for (msg in channel) { // メッセージの受信ループ
when (msg) {
is IncCounter -> counter++
is GetCounter -> msg.response.complete(counter)
}
}
}
suspend fun main() = coroutineScope {
val counter = counterActor() // アクターの作成
withContext(Dispatchers.Default) {
massiveRun { counter.send(IncCounter) } // 多数の増加メッセージを送信
}
// 最終的なカウンターの値を取得
val response = CompletableDeferred<Int>()
counter.send(GetCounter(response))
println("Counter = ${response.await()}")
counter.close() // アクターを終了
}
suspend fun massiveRun(action: suspend () -> Unit) {
val n = 100 // 起動するコルーチンの数
val k = 1000 // 各コルーチンで実行する繰り返しの回数
val time = measureTimeMillis {
coroutineScope {
repeat(n) {
launch {
repeat(k) { action() }
}
}
}
}
println("Completed ${n * k} actions in $time ms")
}
|
参考文献
